Autor

Ken Hall, RCDD NTS
Categorías
Centro de datos de redes de banda anchaEn los centros de datos, la adopción acelerada de la infraestructura y los servicios en la nube están impulsando la necesidad de más ancho de banda, velocidades más rápidas y menor latencia. Dejando de lado el mercado o el enfoque de su instalación, debe considerar los cambios en la arquitectura de su empresa o nube que serán necesarios para respaldar los nuevos requisitos.
Eso significa comprender las tendencias que impulsan la adopción de la infraestructura y servicios en la nube, así como las tecnologías de infraestructura emergentes que le permitirán abordar los nuevos requisitos.
Puede pensar que estar en 10Gb o 100Gb hoy significa que la transición a 400Gb está muy lejos. Pero si suma la cantidad de puertos de 10Gb (o más rápidos) que es responsable de admitir, verá que la necesidad de pasar a 400Gb y más allá, no está tan lejos. A continuación le mostramos algunas cosas en las que debería tomar en cuenta para planificar el futuro.
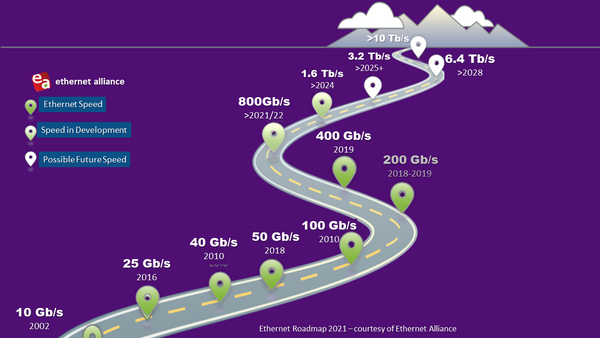
La transición a la infraestructura y el hardware en la nube
A medida que los administradores de centros de datos miran hacia el horizonte, las señales de una evolución basada en la nube están por todas partes:
- Más servidores virtualizados de alto rendimiento
- Mayor ancho de banda y menor latencia
- Conexiones switch-hacia-el-servidor más rápidas
- Velocidades de enlace ascendente/troncal más altas
- Capacidades de expansión rápidas
Para apoyar estos cambios, se permiten velocidades de carril más altas. La progresión de 25 a 50 y posteriormente a 100Gb o más, se ha vuelto común y está comenzando a reemplazar la ruta de migración de 1/10/40Gb. Dentro de la propia nube, el hardware también está cambiando. Hemos pasado de varias redes dispares típicas de un centro de datos heredado a una mayor virtualización mediante la gestión agrupada de hardware y software. Esta virtualización está impulsando la necesidad de enrutar el acceso y la actividad de las aplicaciones de la manera más rápida posible, lo que obliga a muchos administradores de red a preguntarse: "¿cómo diseño mi infraestructura para admitir estas aplicaciones basadas en la nube?"
Vemos que se emplean algunos componentes básicos para ayudar a definir un camino claro de 10Gb a 25Gb a 50Gb y 100 Gb. Muchos administradores de red están utilizando conexiones más directas de máquina a máquina, lo que reduce la latencia al reducir la cantidad de switches entre ellos. Las aplicaciones dependen de que muchas máquinas trabajen juntas, y las redes que las conectan deben evolucionar para seguir satisfaciendo las demandas de servicio y capacidad y, al mismo tiempo, mejorar la eficiencia energética general.
CLIC TO TWEET: Considere la migración hacia 400 Gb (está más cerca de lo que parece).
Conectar más máquinas directamente entre sí mediante interruptores de "high radix" significa menos interruptores (y menor costo y consumo de energía). A medida que aumenta el radix, se pueden conectar más máquinas a un solo switch sin tener que preocuparse por su capacidad o latencia. Es una forma más precisa de ver la capacidad del switch. Las velocidades de conexión del switch también se habilitan cada vez más mediante switches ASIC con velocidades más altas de serialización/deserialización (SerDes). En conjunto, esto forma una estrategia integral para mejorar la capacidad operativa y la eficiencia de los centros de datos a escala de nube.
Transceptores, conectores y chips
La óptica actual SFP, SFP+ o QSFP+ es suficiente para permitir velocidades de enlace de 200Gb. Sin embargo, dar el salto a 400Gb requerirá duplicar la densidad de los transceptores. Aquí es donde entran en juego las tecnologías QSFP-Double Density (QSFP-DD) y el conectable octal (2 veces un cuádruple) de factor de forma pequeño (OSFP).
Los transceptores QSFP-DD son compatibles con versiones anteriores de los puertos QSFP existentes. Se enlazan a módulos ópticos existentes, QSFP+ (40Gb), QSFP28 (100Gb) y QSFP56 (200Gb) por decir algunos ejemplos.
OSFP, como la óptica QSFP-DD, permite el uso de ocho carriles frente a cuatro. Ambos tipos de módulos le permiten colocar 32 puertos en un panel de 1RU. Para admitir la compatibilidad con versiones anteriores, el OSFP requiere un adaptador a QSFP. Una diferencia clave entre las dos tecnologías es que el OSFP apunta a aplicaciones de mayor potencia (<15W*) que QSFP-DD (<12W*). Los MSA mencionan diferentes opciones de conexión óptica: los conectores LC, mini-LC, MPO 8, 12, 16, SN, MDC y CS, que se pueden elegir según la aplicación compatible.
La variedad de opciones tecnológicas para conectores proporciona más formas de romper y distribuir la capacidad adicional que llevan los módulos octales. El MPO de 12 fibras (a veces utilizado con solo 8 fibras) pudo soportar 6 carriles con 2 fibras cada uno. Sin embargo, muchas aplicaciones usaban solo 4 carriles, como el 40GBase-SR4 con 8 fibras. Los módulos octales tienen 8 carriles y pueden admitir 8 conexiones de máquina frente a 4 con los módulos QSFP. Los switches están evolucionando para proporcionar más carriles a velocidades más altas al tiempo que reducen el costo y la potencia de las redes. Los módulos octales permiten que estos enlaces adicionales se conecten a través del espacio de 32 puertos de un switch de 1U. El mantenimiento de la base más alta se logra mediante el uso de una salida de carril del módulo óptico. Los sistemas de cableado de fibra MPO16 y 16 son ideales para admitir este nuevo paradigma de red.

Otros conectores que vale la pena considerar son el SN y el MDC. El SN es un conector de fibra óptica dúplex de factor de forma muy pequeño (VSFF). Está diseñado para servir aplicaciones de interconexión de centros de datos (DCI) de hiperescala, de borde, empresariales y de colocación. Estos conectores incorporan tecnología de férula de 1,25mm y están diseñados para proporcionar opciones de ruptura más flexibles para módulos ópticos de alta velocidad. Los conectores SN y MDC pueden proporcionar 4 conexiones dúplex a un módulo transceptor cuádruple u octal. Sin embargo, no se pueden conectar entre sí y ambos conectores esperan convertirse en la ruta estándar para VSFF. Las primeras aplicaciones de estos conectores se encuentran principalmente en esta aplicación de ruptura de módulo óptico. La pregunta fundamental será qué transceptores estarán disponibles con qué conectores en el futuro.
Por supuesto, no hay límites para la demanda de ancho de banda. Actualmente, el factor limitante no es la cantidad que se puede conectar en la parte frontal del switch, sino la capacidad que puede ofrecer el conjunto de chips en el interior. Un radix más alto se combina con velocidades SERDES más altas para lograr una capacidad neta más alta. El enfoque típico alrededor de 2015 para admitir aplicaciones de 100Gb utiliza carriles de 128 a 25Gb, lo que produce una capacidad de switch de 3.2TB. Llegar a 400Gb requirió aumentar el ASIC a 256 carriles de 50Gb, lo que arroja 12,8TB de capacidad de switch. La siguiente progresión, 256 carriles de 100Gb, nos lleva a 25,6TB. Se están considerando planes futuros para aumentar las velocidades de los carriles a 200Gb; esa es una tarea difícil, que tardará algunos años en perfeccionarse.
Adaptar el cableado y los diseños de la capa física
Por supuesto, el pegamento que mantiene unido todo en su red es el cableado de la capa física. Fácilmente podríamos dedicar toda una serie de blogs solo al tema; en cambio, aquí hay algunos aspectos destacados.
Para ampliar sus tuberías, los centros de datos van más allá de las aplicaciones dúplex tradicionales. Las redes están implementando más configuraciones de 4 pares, 8 pares y 16 pares, según las aplicaciones que admitan. Están utilizando ópticas monomodo y multimodo, WDM dúplex y cableado paralelo combinado para admitir una variedad de topologías de red. El objetivo es aumentar la capacidad y la eficiencia. La solución óptima varía, pero tenemos muchas herramientas a nuestra disposición. La parte difícil es trazar un rumbo que lleve desde su estado actual (a menudo con una base instalada muy grande) a algo que podría estar dos pasos adelante con diferentes topologías de red, tipos de conectores y módulos de cableado como 16f, etc.
Mientras tanto, las configuraciones aplanadas, densas en fibra y de hojas espinales están diseñadas para un tráfico de menor latencia de este a oeste. La tendencia entre los centros de datos y las redes empresariales más grandes es hacia una arquitectura de malla densa de fibra que optimiza el tráfico de este a oeste (a menudo 10 veces el tráfico de norte a sur); sigue siendo una orientación de hoja espinal, pero con menos capas de red y, a menudo, con vistas a niveles más altos. velocidades de conexión del servidor.
La continua evolución de las arquitecturas de tipo malla no es tan importante como noticia. Sin embargo, cuando agregamos los beneficios de los switches de radix más altos, los efectos son significativos. Hoy en día, en la mayoría de las redes de hoja espinal, los switches de hoja alimentan switches ToR situados en la parte superior de cada bastidor de servidores. Este diseño fue óptimo para switches de bajo radix que funcionan a velocidades de conexión de servidor más bajas. Un switch ToR proporcionaría aproximadamente el valor de un rack de conexiones de servidor, con conexiones cortas y de bajo costo entre el servidor y el switch ToR. Pasar a switches de radix superiores significa que, aunque todavía esté usando 32 puertos, hay el doble de carriles disponibles para conectar servidores. Esto brinda una oportunidad fascinante. Con los interruptores de base superior, ahora puede migrar a un diseño en el que varios interruptores de hoja ToR se reemplazan por menos interruptores de hoja ubicados al final de la fila (EoR) o en el medio de la fila (MoR). La eliminación de algunos de los switches significa menos saltos, menor latencia y un diseño más eficiente.
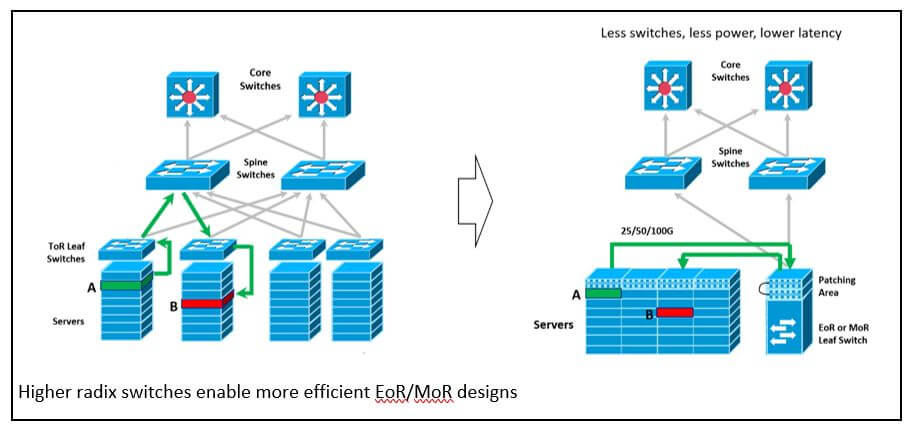
La solución ideal para esta aplicación requerirá que la base se mantenga con 8 conexiones por módulo óptico. El mantenimiento de costos más bajos para esta opción se habilita mediante el uso de ópticas MM menos costosas, así como la nueva compatibilidad con la aplicación 400GSR8 para 8 conexiones de servidor de 50Gb en 100m de cableado OM4. De cara al futuro, el desarrollo en 802.3db tiene como objetivo duplicar la velocidad del carril a 100Gb sobre esta misma infraestructura MMF. Esto es ideal para módulos IA/AA de mayor densidad, que requieren absolutamente velocidades de red de servidor mucho más altas, pero no necesitan enlaces de red más largos que requerirían ópticas SM de mayor costo.
Las conversaciones que debería tener y con quién
Es cierto que hay una larga lista de cosas a considerar con respecto a una migración de alta velocidad a 400Gb y más. La pregunta es, ¿qué deberías estar haciendo? Un gran primer paso es hacer un balance de lo que tiene en su red hoy. ¿Cómo está diseñado actualmente? Por ejemplo, tiene paneles de conexión y cables troncales entre puntos, pero ¿qué pasa con las conexiones? ¿Sus cables troncales tienen clavijas o no? ¿La elección de clavija se alinea con los transceptores que planea usar? Considere las transiciones en la red. ¿Está utilizando MPO a dúplex, una sola MPO a dos MPO? Sin información detallada sobre el estado actual de su red, no sabrá qué implica adaptarla para las aplicaciones del mañana.
Hablando de aplicaciones futuras, ¿cómo es la hoja de ruta tecnológica de su organización? ¿Cuánta pista necesita para preparar su infraestructura para soportar los requisitos cambiantes de velocidad y latencia? ¿Tiene la arquitectura y los recuentos de fibra adecuados?
Estas son todas las cosas que quizás ya esté considerando, pero ¿quién más está en la mesa? Si está en el equipo de la red, debe estar en diálogo con sus contrapartes en el lado de la infraestructura. Pueden ayudarlo a comprender lo que está instalado y puede alertarlos sobre los requisitos y planes futuros que pueden estar más adelante.
Por último, pero no menos importante, nunca es demasiado pronto para traer expertos externos que puedan brindarle un par de ojos nuevos y una perspectiva diferente. Si bien nadie conoce sus necesidades mejor que usted, es más probable que un experto independiente maneje mejor las tecnologías existentes y emergentes, las tendencias de diseño y las mejores prácticas.












