La migración a 400G/800G: Parte I
La planificación para afrontar los retos futuros de los data centers empieza hoy. La hoja de ruta del Ethernet explicada.
En los data centers, el panorama está cambiando… de nuevo.
La acelerada adopción de la infraestructura y los servicios en la nube está impulsando la necesidad de un mayor ancho de banda, velocidades más rápidas y un rendimiento de menor latencia. El avance de la tecnología de conmutador y servidor está forzando cambios de cableado y arquitecturas. Independientemente del mercado o enfoque de su instalación, debe considerar los cambios en su empresa o en la arquitectura de la nube que probablemente serán necesarios para soportar los nuevos requerimientos. Eso significa comprender las tendencias que impulsan la adopción de los servicios y la infraestructura de nube, así como las tecnologías de infraestructura emergentes que permitirán a su organización abordar dichos nuevos requerimientos. A continuación le mostramos algunas cosas en las que debería tomar en cuenta para planificar el futuro.
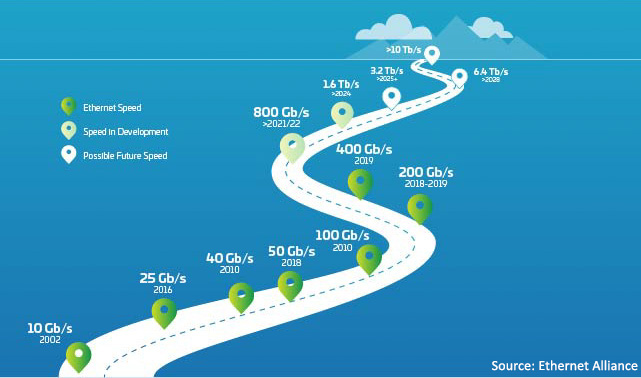
Figura 1: Hoja de ruta del Ethernet
¿Desea leer sin conexión?
Descargue una versión en PDF de este artículo para volver a leerla más tarde.
Manténgase informado
Suscríbase a The Enterprise Source y obtenga actualizaciones cuando se publiquen nuevos artículos.
Uso global de datos
Por supuesto,parte central del cambio son las tendencias globales que están transformando las expectativas de los consumidores y la demanda de comunicaciones más rápidas, como:
- Crecimiento explosivo del tráfico en las redes sociales
- Despliegue de servicios 5G, gracias a la densificación masiva de células pequeñas
- Aceleración de implementaciones de IoT e IIoT (IoT industrial)
- Cambio del trabajo tradicional en la oficina a opciones remotas
Crecimiento de proveedores de hiperescala
A nivel mundial, los data centers a hiperescala pueden ser menos de una docena, pero su impacto en el paisaje general de los data centers es importante. De acuerdo con una investigación reciente, el mundo navegó en Internet el equivalente a 1,25 miles de millones de años solo en 2020.1 Alrededor del 53 % de ese tráfico pasa por una instalación de hiperescala. 2
Colaboración de hiperescala con instalaciones de data center multi-tenant (MTDC/coubicación)
A medida que aumenta la demanda de un rendimiento de latencia más bajo, los proveedores de hiperescala y escala de nube trabajan para acercar su presencia al usuario final/dispositivo final. Muchos se están asociando con MTDC o data centers de coubicación para localizar sus servicios en la llamada red “periférica”.3 Cuando la periferia está físicamente cerca, el descenso de latencia y de costos de red amplía el valor de los nuevos servicios de baja latencia. Como resultado, el crecimiento del campo de la hiperescala está forzando a los MTDC y a las instalaciones de coubicación a adaptar sus infraestructuras y arquitecturas para dar soporte al aumento de las demandas de tráfico y escala que son más típicas de los data centers de hiperescala. Al mismo tiempo, estos data centers más grandes deben seguir siendo flexibles para las solicitudes de los clientes de conexiones cruzadas a plataformas de proveedores de nube.
Redes de malla de tela y leaf-spine
La necesidad de admitir aplicaciones de baja latencia, alta disponibilidad y un gran ancho de banda no se limita a data centers de hiperescala y de coubicación. Ahora, todas las instalaciones de data centers deben replantearse su capacidad de gestionar las crecientes demandas de los usuarios finales y las partes interesadas. En respuesta, los administradores de data centers están avanzando rápidamente hacia redes de mallas con mayor densidad de fibra. La conectividad de cualquier tipo, los cables troncales de fibra más altos y las nuevas opciones de conectividad permiten a los operadores de red admitir velocidades de línea cada vez mayores mientras se preparan para realizar la transición a 400 Gigabits por segundo4 (G).
Cómo habilitar inteligencia artificial (AI) y aprendizaje automático (ML)
Además, los proveedores de data centers más grandes, impulsados en parte por IoT y aplicaciones de ciudades inteligentes, están recurriendo a la AI y al ML para ayudar a crear y refinar los modelos de datos que ofrecen capacidades de computación periférica casi en tiempo real. Además de tener el potencial de permitir un nuevo mundo de aplicaciones (imagínese automóviles autoconducidos viables comercialmente), estas tecnologías requieren grupos enormes de datos, a menudo denominados lagos de datos, y una potencia informática masiva dentro de los data centers, así como líneas lo suficientemente grandes para llevar los modelos refinados al extremo cuando sea necesario.5
Preparación para el cambio a 400G/800G
Solo porque actualmente esté trabajando a 40G o incluso a 100G, no se deje llevar por una falsa sensación de seguridad. Si la historia de la evolución del data center nos ha enseñado algo, es que la velocidad del cambio, ya en sea el ancho de banda, la densidad de la fibra o las velocidades de línea, se acelera exponencialmente. La transición a 400G está más cerca de lo que se cree. ¿No está convencido? Sume el número de puertos 10G (o más rápidos) que está soportando actualmente e imagine que progresan a 100G: se dará cuenta de que la necesidad de 400G (y más) no está tan lejos.
A medida que los administradores de centros de datos miran hacia el horizonte, las señales de una evolución basada en la nube están por todas partes:
Más
servidores virtualizados de alto rendimiento
Mayores
ancho de banda y menor latencia
Mayor rapidez
de conexiones de conmutador a servidor
Mayores
velocidades de enlace ascendente/red central
Rápidas
capacidades de expansión
Dentro de la propia nube, el hardware está cambiando. Varias redes dispares típicas de un data center heredado han evolucionado hacia entornos más virtualizados que utilizan recursos de hardware agrupados y gestión impulsada por software. Esta virtualización está impulsando la necesidad de enrutar el acceso y la actividad de las aplicaciones de la manera más rápida posible, lo que obliga a muchos administradores de red a preguntarse: "¿cómo diseño mi infraestructura para admitir estas aplicaciones basadas en la nube?"
La respuesta comienza por habilitar velocidades más altas por línea. La progresión de 25 a 50 hasta 100G y superior es vital para llegar a 400G y más allá, y ha comenzado a reemplazar la ruta de migración tradicional a 1/10G. Pero no se trata solo de aumentar la velocidad de las líneas, hay mucho más. Tenemos que profundizar un poco más.
El sector está alcanzando un punto de inflexión. La adopción de 400G ha aumentado muy rápidamente, pero se espera que en breve comience el ascenso a 800G incluso más deprisa que a 400G. Como cabe esperar, no hay una respuesta sencilla a la pregunta sobre“¿quién o qué está impulsando la transición a 400G?” Hay todo tipo de factores en juego, muchos de los cuales están entrelazados. Las nuevas tecnologías permiten un menor coste por bit cuando aumentan las tasas de línea. Según los últimos datos, las tasas de línea de 100G se combinarán con puertos de conmutación octal para ofrecer opciones 800G al mercado a partir de 2022. Sin embargo, estos puertos se utilizan de varias maneras, como se ilustra en los datos de Light Counting6 donde 400G y 800G se dividen principalmente en 4X u 8X 100G. Esta aplicación de conexión es el impulsor inicial de estas nuevas aplicaciones ópticas.
Figura 2: Envíos de puertos Ethernet de data centers
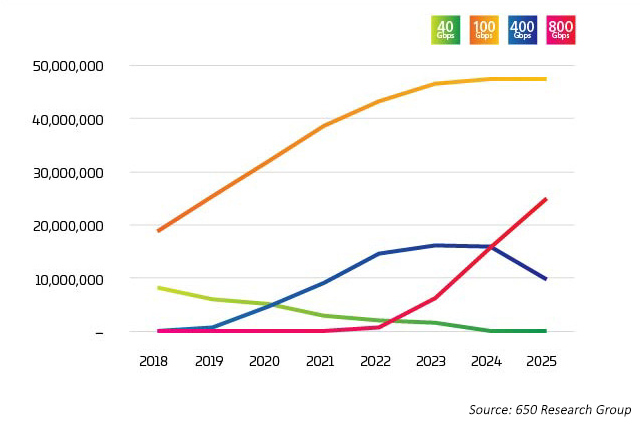
En la red de datos, la capacidad es cuestión de comprobar y equilibrar servidores, conmutadores y conectividad. Cada uno impulsa al otro a ser más rápido y menos costoso, para realizar un seguimiento eficiente de la demanda producida por el aumento de conjuntos de datos, IA y ML. Durante años, la tecnología de conmutación fue el principal inconveniente. Con la introducción de StrataXGS® Tomahawk® de Broadcom3, los administradores de data centers ahora pueden aumentar las velocidades de conmutación y enrutamiento a 12,8 Terabits/s (Tb/s) y reducir su coste por puerto en un 75 por ciento. El chip de conmutación 4 Tomahawk de Broadcom, con un ancho de banda de 25 Tb/s., proporciona al sector de los data centers más capacidad de conmutación para mantenerse por delante de las crecientes cargas de trabajo de AI y ML. En la actualidad, este chip admite puertos de 64x 400G; pero con una capacidad de 25,6 Tb/s, la tecnología de semiconductores nos lleva por un camino en el que en el futuro podríamos ver puertos de 32x 800G en un solo chip. 32, casualmente, es el número máximo de QSFP-DD u OSFP (transceptores de 800 G) que se pueden presentar en un panel frontal de conmutadores 1U.
Por lo tanto, el factor limitador es la capacidad de procesamiento del CPU. ¿No es así? Incorrecto. A principios de este año, NVIDIA presentó su nuevo chip Ampere para servidores. Resulta que los procesadores utilizados en los juegos son perfectos para gestionar el procesamiento basado en inferencias y la capacitación que se necesita para AI y ML. Según NVIDIA, una máquina basada en Ampere puede hacer el trabajo de 120 servidores con tecnología Intel.
Figura 3: Velocidades de Ethernet
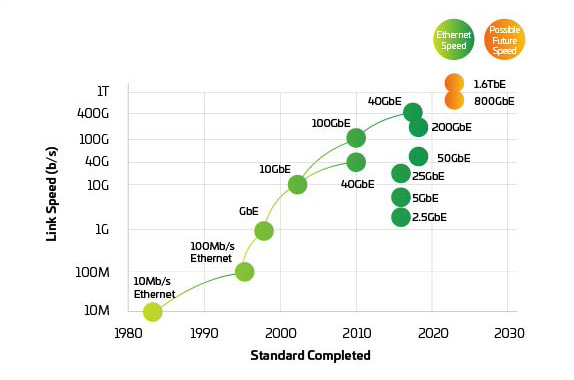
Con los conmutadores y servidores preparados para dar soporte a 400G y 800G en el momento en que se necesitan, la presión pasa a la capa física para mantener la red equilibrada. IEEE 802.3bs, aprobado en 2017, abrió el camino para Ethernet 200G y 400G. Sin embargo, el IEEE acaba de completar su evaluación de ancho de banda con respecto a 800G y más allá. El IEEE ha puesto en marcha un grupo de estudio para identificar los objetivos de las aplicaciones más allá de 400G y, dado el tiempo necesario para desarrollar y adoptar nuevos estándares, es posible que ya estemos rezagados. El sector está trabajando conjuntamente para introducir 800G y empezar a trabajar hacia 1.6T y más, a la vez que mejora la potencia y el coste por bit.
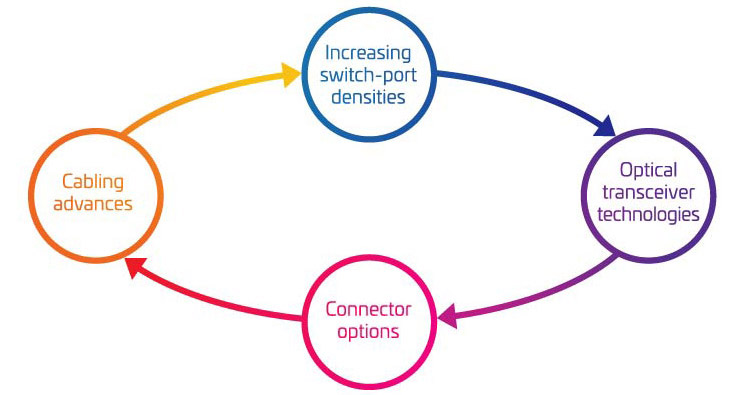
Los cuatro pilares de la migración a 400G/800G
A medida que empiezan a tener en cuenta los aspectos básicos de apoyar su migración a 400G, es fácil sentirse abrumado por todas las piezas móviles implicadas. Para ayudarle a comprender mejor las variables clave que deben tenerse en cuenta, las hemos agrupado en cuatro áreas principales:
- Aumento de las densidades de los puertos de conmutación
- Tecnologías de transceptor óptico
- Opciones de conectores
- Avances en el cableado
Juntas, estas cuatro áreas representan una gran parte de su caja de herramientas para la migración. Utilícelas para ajustar su estrategia de migración a sus necesidades actuales y futuras.
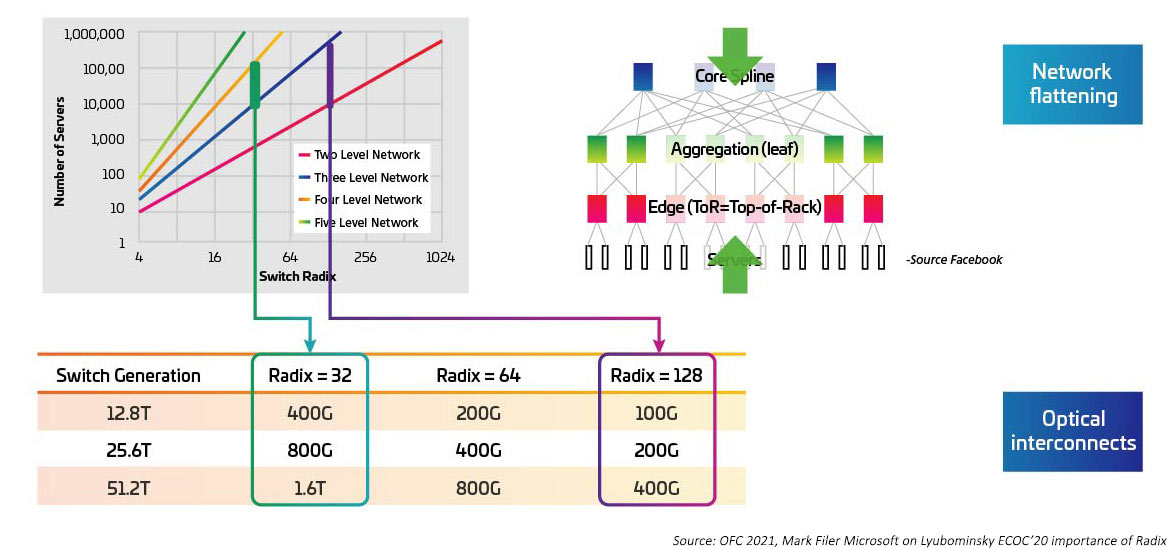
Las velocidades de conmutación están aumentando a la par que el serializador/deserializador (SERDES) proporciona la E/S eléctrica para el movimiento ASIC de conmutación de 10G, 25G, 50G. Se espera que SERDES alcance 100G una vez que IEEE802.3ck se convierta en un estándar ratificado. Los circuitos integrados específicos de la aplicación del conmutador (ASIC) también están aumentando la densidad del puerto de E/S (también conocido como radix). Los ASIC de mayor radix admiten más conexiones de dispositivos de red, lo que ofrece la posibilidad de eliminar los conmutadores de capa superior de rack (ToR). Esto, a su vez, reduce el número total de conmutadores necesarios para una red en la nube. (Un data center con 100.000 servidores puede ser compatible con dos niveles de conmutación con un RADIX de 512). Los ASIC de mayor radix se traducen en un menor CAPEX (menos conmutadores), un menor OPEX (menos energía necesaria para alimentar y enfriar menos conmutadores) y un mejor rendimiento de la red gracias a latencias más bajas.
Figura 4: Efectos de conmutadores Radix más altos en el ancho de banda del conmutador
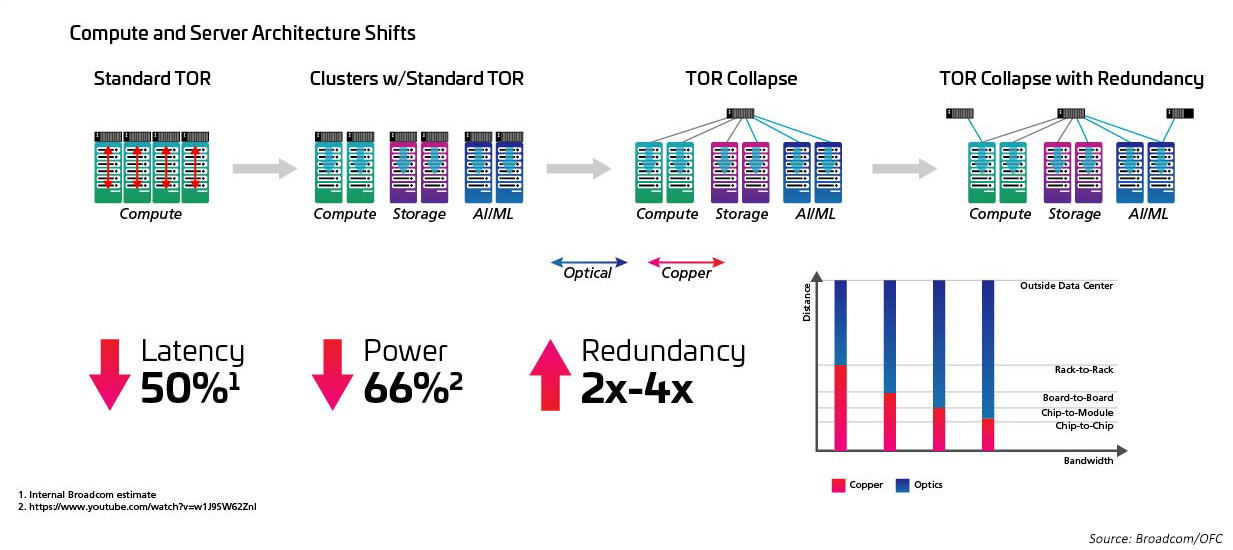
Estrechamente relacionado con el aumento de radix y la velocidad de conmutación está el paso de una topología de la parte superior del rack (ToR) a una configuración de mitad de fila (MoR) o final de fila (EoR), y la ventaja que el enfoque de cableado estructurado mantiene al facilitar las numerosas conexiones entre los servidores en fila y los conmutadores MoR/EoR. Se requiere la capacidad de gestionar el gran número de conexiones de servidor con mayor eficiencia para hacer uso de los nuevos conmutadores de alta velocidad. Esto, a su vez, requiere nuevos módulos ópticos y cableado estructurado, como los definidos en el estándar IEEE802 2.3 cm. El estándar IEEE802 2.3 cm admite las ventajas de los transceptores conectables para su uso con aplicaciones de red de servidores de alta velocidad en grandes data centers que definen ocho conexiones de host a un transceptor QSFP-DD.
Figura 5: Arquitecturas que cambian de ToR a MoR/EoR
Al igual que la adopción del factor de forma QSFP28 impulsó la adopción de 100G al ofrecer alta densidad y menor consumo de energía, el salto a 400G y 800G se está habilitando mediante nuevos factores de forma de transceptor. La óptica SFP, SFP+ o QSFP+ actual es suficiente para habilitar velocidades de enlace de 200G. Sin embargo, si se hace el salto a 400G, será necesario duplicar la densidad de los transceptores. No hay problema.
Los acuerdos de múltiples fuentes (MSAs) de QSFP-Double Density (QSFP-DD7) y factor de forma octal (2 veces uno cuádruple) pequeño y enchufable (OSFP8) permiten a las redes duplicar el número de conexiones de E/S eléctricas al ASIC. Esto no solo permite sumar más E/S para alcanzar velocidades agregadas más altas, sino que también permite que el número total de conexiones de E/S ASIC llegue a la red.
El factor de forma del conmutador 1U con 32 puertos QSFP-DD coincide con 256 (32x8) E/S ASIC. De esta forma, podemos crear enlaces de alta velocidad entre conmutadores (8*100 u 800G), pero también podemos mantener el número máximo de conexiones al conectar servidores.
Nuevos formatos de transceptor
Al mercado óptico para 400G le impulsan el costo y el rendimiento, ya que los fabricantes originales intentan alcanzar al punto óptimo de los data centers a escala de la nube y la hiperescala. En 2017, CFP8 se convirtió en el factor de forma del módulo 400G de primera generación que se utilizaba en enrutadores centrales e interfaces de cliente de transporte DWDM. El transceptor CFP8 fue el tipo de factor de forma 400G especificado por el MSA CFP. Las dimensiones del módulo son ligeramente más pequeñas que CFP2, mientras que la óptica admite E/S eléctricas CDAUI-16 (16x25G NRZ) o CDAUI-8 (8x50G PAM4). En cuanto a la densidad de ancho de banda, admite respectivamente ocho veces y cuatro veces la densidad de ancho de banda del transceptor CFP y CFP22.
Los módulos de factor de forma 400G de “segunda generación” incluyen QSFP-DD y OSFP. Los transceptores QSFP-DD son compatibles con versiones anteriores de los puertos QSFP existentes. Se basan en el éxito de los módulos ópticos existentes, QSFP+ (40G), QSFP28 (100G) y QSFP56 (200G).
OSFP, como la óptica QSFP-DD, permite el uso de ocho carriles frente a cuatro. Ambos tipos de módulos admiten 32 puertos en una tarjeta 1RU (conmutador). Para admitir la compatibilidad con versiones anteriores, el OSFP requiere un adaptador a QSFP.
Figura 6: Comparación entre transceptor OSFP y QSFP-DD

Esquemas de modulación
Los ingenieros de redes han utilizado durante mucho tiempo la modulación de no retorno a cero (NRZ) para 1G, 10G y 25G, utilizando la corrección de errores directa (FEC) del lado del host para permitir transmisiones de mayor distancia. Para pasar de 40G a 100G, la industria simplemente pasó a la paralelización de las modulaciones NRZ 10G/25G, utilizando también FEC del lado del host para las distancias más largas. Cuando se trata de alcanzar velocidades de 200G/400 G y más rápidas, se necesitan nuevas soluciones.
Figura 7: Se utilizan esquemas de modulación de alta velocidad para habilitar las tecnologías 50G y 100G
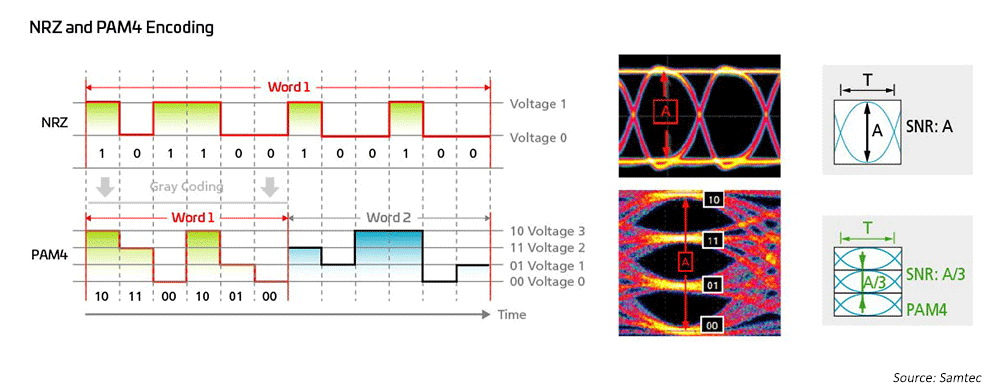
Como resultado, los ingenieros de redes ópticas han recurrido a la modulación de amplitud de pulso de cuatro niveles (PAM4) para sacar provecho de arquitecturas de red de ancho de banda ultraalto; PAM4 es la solución actual para 400GPAM4. Esto se basa en una gran medida de IEEE802.3, que ha completado nuevos estándares Ethernet para velocidades de hasta 400G (802.3bs/cd/cu) para aplicaciones multimodo (MM) y monomodo (SM). Hay disponibles todo tipo de opciones de conexión para adaptarse a diversas topologías de red en data centers a gran escala.
Los esquemas de modulación más complejos implican la necesidad de una infraestructura que pueda proporcionar una mejor pérdida de retorno y atenuación.
Predicciones: comparación entre PSE y QSFP-DD
Con respecto a OSFP frente a QSFP-DD, es demasiado pronto para saber de qué manera irá el sector ahora mismo; ambos factores de forma están respaldados por los principales proveedores de conmutadores de Ethernet de data centers y ambos tienen un gran soporte al cliente. Quizá la empresa prefiera QSFP-DD como una mejora de la óptica basada en QSFP actual. OSFP parece ir más lejos con la introducción de OSFP-XD, ampliando el número de líneas a 16 con vistas a tasas de líneas 200G en el futuro.
Para velocidades de hasta 100G, QSFP se ha convertido en una solución imprescindible debido a su tamaño, potencia y ventaja de costo en comparación con los transceptores dúplex. QSFP-DD se basa en este éxito y proporciona compatibilidad con versiones anteriores que permite el uso de transceptores QSFP en un conmutador con la nueva interfaz DD.
Con vistas al futuro, muchos creen que la huella del QSFP-DD de 100G será popular en los próximos años. Puede que se favorezca la tecnología OSFP para enlaces ópticos DCI o las que requieran específicamente una mayor potencia y más E/S ópticas. Los defensores de OSFP prevén transceptores de 1.6T y tal vez 3.2T en el futuro.

La óptica co-empaquetada (CPO) proporciona una ruta alternativa a 1.6T y 3.2T. Sin embargo, los CPO necesitarán un nuevo ecosistema que pueda acercar la óptica a los ASIC del conmutador para lograr mayores velocidades a la vez que se reduce el consumo de energía. Esta pista se está desarrollando en el Foro de interconexión óptica (Optical Internetworking Forum-OIF). El OIF está debatiendo actualmente las tecnologías que podrían ser más adecuadas para la “próxima tasa”, y muchos discuten una duplicación a 200G. Otras opciones incluyen más líneas, tal vez 32, ya que algunos creen que con el tiempo se necesitarán más líneas y tasas de líneas más altas para mantener el ritmo de la demanda de la red a un coste de red asequible.
La única predicción segura es que la infraestructura de cableado debe tener la flexibilidad integrada para admitir sus futuras topologías de red y requisitos de enlace. Aunque los astrónomos llevan mucho tiempo sosteniendo que “cada fotón cuenta”, puesto que los diseñadores de redes buscan reducir la energía por bit a unos pocos pJ/Bit9, es importante la conservación a todos los niveles. El cableado de alto rendimiento ayudará a reducir la sobrecarga de la red.
Los switches están evolucionando para proporcionar más carriles a velocidades más altas al tiempo que reducen el costo y la potencia de las redes. Los módulos octales permiten que estos enlaces adicionales se conecten a través del espacio de 32 puertos de un conmutador 1U. El mantenimiento de la base más alta se logra mediante el uso de una salida de carril del módulo óptico.
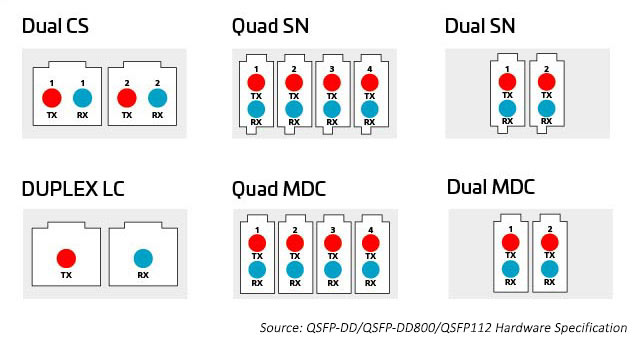
La variedad de opciones de tecnología de conectores proporciona más formas de conectar y distribuir la capacidad adicional que proporcionan los módulos octal. Los conectores incluyen conectores de 8, 12, 16 y 24 fibras en paralelo multi-push en conectores LC, SN, MDC y CS de fibra dúplex y (MPO) ). Consulte a continuación para obtener más información.
Figura 8: Opciones para distribuir la capacidad de los módulos octales
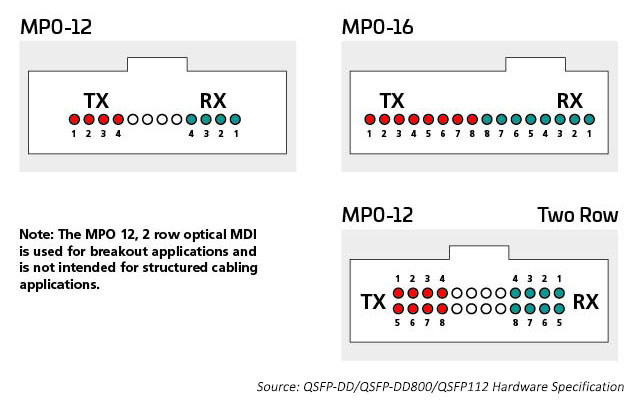
Conectores MPO
Hasta hace poco, el método principal de conexión de conmutadores y servidores dentro del data center implicaba el cableado organizado alrededor de 12 o 24 fibras, normalmente utilizando conectores MPO. La introducción de la tecnología octal (ocho líneas de conmutación por puerto de conmutación) permite a los data centers hacer coincidir el mayor número de E/S ASIC (actualmente 256 por ASIC de conmutación) con los puertos ópticos. Esto genera el número máximo de E/S disponibles para conectar servidores u otros dispositivos.
Las E/S ópticas utilizan conectores adecuados para el número de líneas ópticas que se usan. Un transceptor 400G puede tener un conector LC dúplex único con una E/S óptica 400G; también podría tener 4 X E/S ópticas 100G que requieran 8 fibras. Los conectores dúplex MPO12, o quizás 4 SN, encajarán dentro de la carcasa del transceptor y proporcionarán las 8 fibras que necesita esta aplicación. Se requieren dieciséis fibras para que coincidan con las E/S 8 eléctricas y ópticas, preservando el radix del conmutador ASIC. Los puertos ópticos pueden ser monomodo o multimodo, dependiendo de la distancia que el enlace esté diseñado para soportar.
Por ejemplo, la tecnología multimodo sigue proporcionando las velocidades de datos ópticos de alta velocidad más rentables para enlaces de corto alcance en el data center. Los estándares IEEE admiten 400G en una tecnología de enlace simple (802,3400G SR4.2), que utiliza cuatro fibras para transmitir y cuatro fibras para recibir; cada fibra transporta dos longitudes de onda. Este estándar amplía el uso de técnicas de multiplexación por división de longitud de onda bidireccional (BiDi WDM) y originalmente se diseñó para admitir enlaces de conmutación a conmutación. Este estándar utiliza el conector MPO12 y fue el primero en optimizar con MMF OM5.
Mantener el radix del switch es importante cuando hay que conectar a la red muchos dispositivos, como los racks de servidores. 400G SR8, que se aborda en el estándar IEEE 802.3cm (2020), admite ocho conexiones de servidor que utilizan ocho fibras para transmitir y ocho fibras para recibir. Esta aplicación ha obtenido apoyo entre los operadores de la nube. Se están implementando arquitecturas MPO-16 para optimizar esta solución.
Los estándares monomodo admiten aplicaciones de mayor alcance (por ejemplo, de conmutación a conmutación). IEEE 400G-DR4 admite el alcance de 500 metros con 8 fibras. Esta aplicación puede ser compatible con MPO-12 o MPO-16. El valor del enfoque de 16 fibras es mayor flexibilidad; los administradores de data centers pueden dividir un circuito 400G en enlaces 50/100G manejables. Por ejemplo, una conexión de 16 fibras en el conmutador puede dividirse para admitir hasta ocho servidores que se conecten a 50/100G al mismo tiempo que se ajusta a la velocidad de la línea eléctrica. Los conectores de 16 fibras MPO tienen una clave diferente para evitar la conexión con los conectores de 12 fibras MPO.
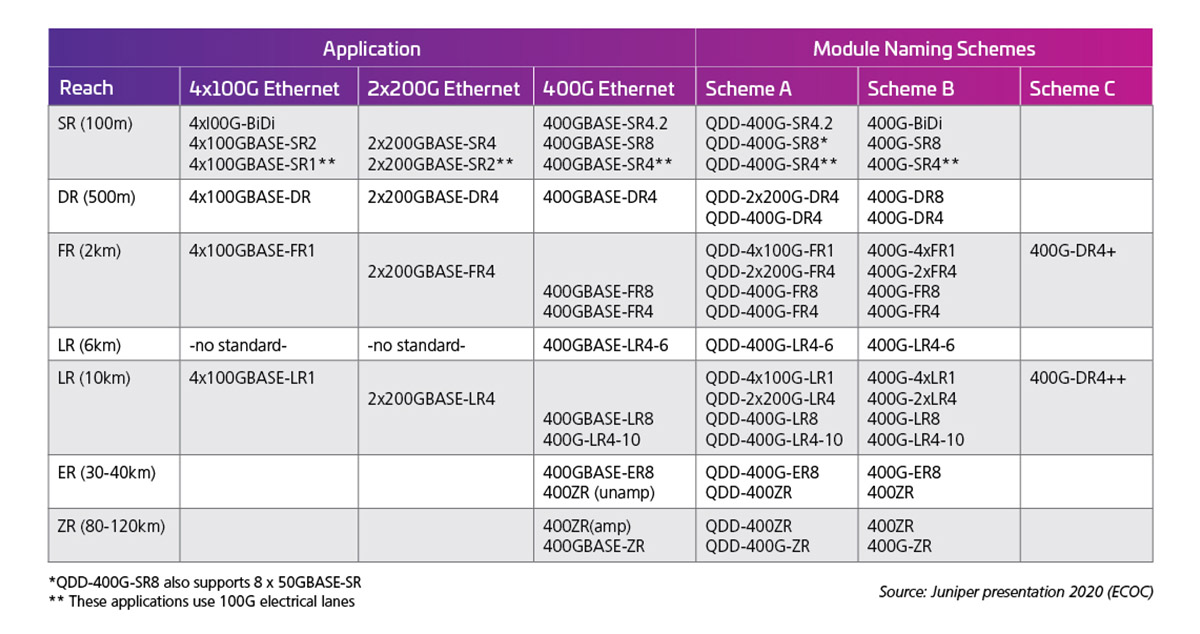
La tasa de línea eléctrica determina entonces las capacidades de salida de la interfaz óptica. La Tabla 1 muestra ejemplos de las posibilidades/estándares del módulo 400G (50G X 8).
Tabla 1: QSFP-DD de 400G de capacidad con líneas eléctricas de 50G
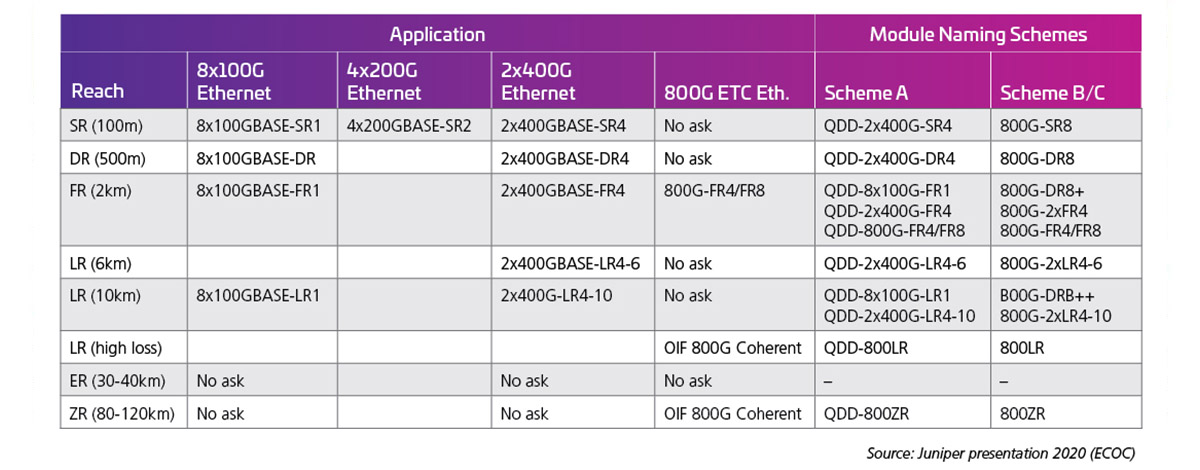
Cuando las velocidades de las líneas se duplican a 100G, se pueden utilizar las siguientes interfaces ópticas. En el momento de redactar este documento, no se han completado los estándares de tasa de línea 100G (802,3 ck); sin embargo, se están lanzando productos tempranos y muchas de estas posibilidades, de hecho, están enviándose. La tabla 2, presentada en ECOC 2020 por J. Maki (Juniper), muestra el interés inicial del sector en los módulos 800G.
Tabla 2: QSFP-DD de 800G de capacidad con líneas eléctricas de 100G
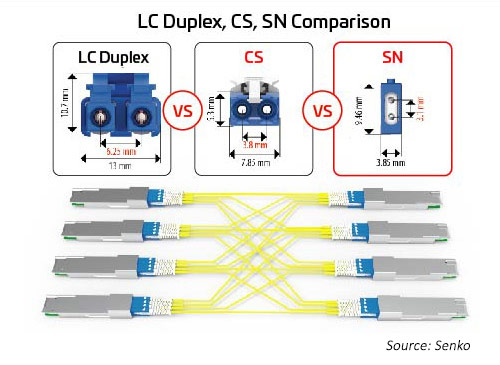
Conectores dúplex
A medida que aumenta el número de líneas y las velocidades de los líneas, la división de las E/S ópticas se vuelve más atractiva. Como se mencionó anteriormente, los módulos octal pueden admitir opciones de conectores para 1, 2, 4 o 8 enlaces dúplex. Todas estas opciones se pueden acomodar utilizando un conector MPO; sin embargo, esa opción puede no ser tan eficiente como los conectores dúplex independientes. Un conector dúplex con una huella menor puede ayudar a habilitar estas opciones. El SN, un conector de fibra óptica dúplex con factor de forma muy pequeño (VSFF), se adapta a esta aplicación. Incorpora la misma tecnología de férula de 1,25 mm que se usó anteriormente en los conectores LC. Como resultado, ofrece el mismo rendimiento óptico y la misma resistencia, pero se centra en opciones de conexión más flexibles para módulos ópticos de alta velocidad. El conector SN puede proporcionar cuatro conexiones dúplex a un módulo transceptor octal. Las primeras aplicaciones para el SN son principalmente para habilitar aplicaciones de conexión de módulo óptico.
Figura 10: Relación de tamaño entre los principales conectores dúplex y las aplicaciones de conexión para la migración 400G/800G
¿Límites de velocidad del conector?
Normalmente los conectores no dictan la velocidad, la economía sí. Las tecnologías ópticas fueron desarrolladas e implementadas inicialmente por proveedores de servicios que tenían los medios financieros y las demandas de ancho de banda para respaldar su desarrollo, así como los enlaces de larga distancia que están más enlazados económicamente utilizando el menor número de fibras. Hoy en día, la mayoría de los proveedores de servicios prefieren la tecnología de conectores simples o dúplex combinada con protocolos de transporte óptico que utilizan tecnologías de conectores de fibra única como LC o SC.
Sin embargo, estas soluciones de larga distancia pueden ser demasiado caras, especialmente cuando hay cientos o miles de enlaces y distancias de enlace más cortas que atravesar; ambas condiciones son típicas de un data center. Por lo tanto, los data centers a menudo implementan ópticas paralelas. Dado que los transceptores paralelos proporcionan un menor costo por Gigabit, la conectividad basada en MPO es una buena opción para distancias más cortas. Por lo tanto, las opciones de conectores actuales no se basan tanto en la velocidad, sino en el número de líneas de datos que pueden admitir, el espacio que ocupan y el impacto de los precios en los transceptores y las tecnologías de conmutación.
En el análisis final, la gama de transceptores ópticos y conectores ópticos se está expandiendo, impulsada por una amplia variedad de diseños de red. Los data centers a hiperescala pueden optar por implementar un diseño óptico muy personalizado; dada la escala de estos impulsores del mercado, los organismos de estándares y los fabricantes originales a menudo responden desarrollando nuevos estándares y oportunidades de mercado. Como resultado, la inversión y la escala lideran el sector en nuevas direcciones y los diseños de cableado evolucionan para satisfacer estos nuevos requisitos.
Conozca lo último en avances de cableado, lea La migración a 400G/800G: Parte II.

Propel™: la plataforma de fibra de alta velocidad

Soluciones para data centers para empresas

Solución
Data centers de nube e hiperescala

Solución
Data Centers multi-tenant

Solución
Data centers para proveedores de servicios

Perspectivas
Fibra multimodo: ficha técnica
Recursos
Biblioteca de migración a alta velocidad

Información de especificación
OSFP MSA

Información de especificación
QSFP-DD MSA
Especificación
Hardware QSFP-DD


A primera vista, el campo de posibles socios de infraestructura que compiten por su negocio parece estar bastante abarrotado. No faltan proveedores dispuestos a venderle fibra y conectividad. Sin embargo, a medida que mira más de cerca y se considera lo que es fundamental para el éxito a largo plazo de su red, las opciones empiezan a reducirse. Esto se debe a que se necesita algo más que fibra y conectividad para impulsar la evolución de su red... mucho más. Ahí es donde CommScope destaca.
Rendimiento mejorado: La historia de innovación y rendimiento de CommScope abarca más de 40 años: nuestra fibra TeraSPEED® monomodo debutó tres años antes del primer estándar OS2, y nuestro innovador multimodo de banda ancha dio lugar al multimodo OM5. En la actualidad, nuestras soluciones de fibra y cobre de extremo a extremo y la inteligencia AIM respaldan sus aplicaciones más exigentes con el ancho de banda, las opciones de configuración y el rendimiento de pérdida ultrabaja que necesita para crecer con confianza.
Agilidad y adaptabilidad: Nuestra cartera modular le permite responder rápida y fácilmente a las cambiantes demandas de su red. Monomodo y multimodo, conjuntos de cables preterminados, paneles de conexiones altamente flexibles, componentes modulares, conectividad MPO de 8, 12, 16 y 24 fibras, conectores paralelos y dúplex con factor de forma muy pequeño. CommScope le mantiene rápido, ágil y con ventaja.
Preparados para el futuro: Al migrar de 100G a 400G, 800G y más allá, nuestra plataforma de migración de alta velocidad proporciona un camino claro y elegante hacia densidades de fibra más altas, velocidades de línea más rápidas y nuevas topologías. Reduzca los niveles de red sin reemplazar la infraestructura de cableado, cambie a redes de servidores de baja latencia y mayor velocidad a medida que sus necesidades evolucionen. Una plataforma sólida y ágil que le llevará del presente al futuro.
Fiabilidad garantizada: Con nuestro sistema de aseguramiento de aplicaciones, CommScope garantiza que los enlaces que diseñe actualmente cumplirán con sus requisitos de aplicación años después. Respaldamos ese compromiso con un programa de servicio de ciclo de vida integral (planificación, diseño, implementación y operación), un equipo global de ingenieros de aplicaciones de campo y la férrea garantía de 25 años de CommScope.
Disponibilidad global y compatibilidad local: La presencia global de CommScope incluye la fabricación, distribución y servicios técnicos locales que abarcan seis continentes y cuenta con 20.000 profesionales apasionados. Estamos a su disposición, cuando y donde nos necesite. Nuestra red global de socios le garantiza que cuenta con los diseñadores, instaladores e integradores certificados para que su red siga avanzando.





1 Digital Trends (Tendencias digitales) 2020; thenextweb.com
2 The Golden Age of HyperScale (La edad de oro de la hiperescala); Data Centre Magazine; 30 de noviembre de 2020
3 https://attom.tech/wp-content/uploads/2019/07/TIA_Position_Paper_Edge_Data_Centers.pdf
4 https://www.broadcom.com/blog/switch-phy-and-electro-optics-solutions-accelerate-100g-200g-400g-800g-deployments
5The Datacenter as a Computer Designing Warehouse-Scale Machines (El data center como computadora de diseño de máquinas a escala de almacén). Tercera edición. Luiz André Barroso, Urs Hölzle y Parthasarathy Ranganathan Google LLC. Morgan & Claypool Publishers pág. 27
6 Presentación de LightCounting para la conferencia ARPA-E - octubre de 2019.pdf (energy.gov)
7 http://www.qsfp-dd.com/wp-content/uploads/2021/05/QSFP-DD-Hardware-Rev6.0.pdf
8 https://osfpmsa.org/assets/pdf/OSFP_Module_Specification_Rev3_0.pdf
9 Andy Bechtolsheim, Arista, OFC '21
El cambio a 400 Gb (está más cerca de lo que cree)
Obtenga la lista preliminar de los indicios que señalan la evolución de DC basada en la nube.