Author

Kam Patel
Categories
Data CenterIt’s no secret that the amount of data flowing into and through data centers is increasing by orders of magnitude each year. This alone is forcing network managers to rethink everything from their outside fiber plant to the network topologies used to move, route and distribute petabytes of data. At the same time, the very nature of the data is quickly changing as well. The trend toward more customer applications that require ultra-reliable, ultra-low-latency performance and more processing resources at the edge has brought into question the definition of what a data center is or needs to be. The result is an interesting dichotomy.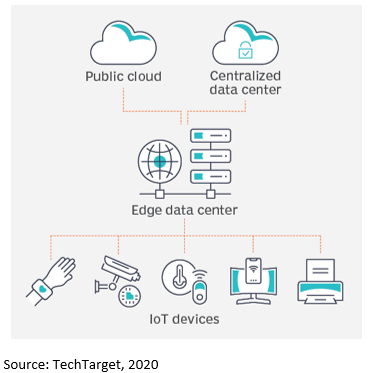
On the one hand, the move to a more efficient cloud-based virtualized environment enables data centers to take advantage of economies of scale. By pooling active equipment in a centralized structure (not unlike a mobile network C-RAN) data centers can realize substantial savings in terms of power, maintenance and other operational efficiencies.
On the other hand, the influx of ultra-reliable, ultra-low-latency data from applications like manufacturing automation, self-driving vehicles, and tele-surgery means more compute resources need to be located closer to the devices and people producing and consuming the data. This trend dictates pushing more active equipment to the “edge.” But what exactly does that mean? Where exactly is the edge? Localized and distributed street-level cabinets, each with a few racks? Metro edge-based data centers populated with a dozen or so rows? Or some combination of the two? The answer will be related to the latency performance these new applications require.
By 2025, 85 percent of infrastructure strategies will integrate on-premises, colocation, cloud and edge delivery options, compared with 20 percent in 2020.[i]
In a 2020 article, Gartner points out that, to properly understand and address the metamorphosis taking place, start with the workload requirements of the data—not the current physical makeup of the data center landscape. In other words, the role of IT is not to design, deploy and maintain data centers; their job is to satisfy the disparate workload requirements of the various applications and customers in the most cost-efficient and sustainable way possible. Form must follow function, not dictate it. So, let’s look at the applications that are already informing the future of data center design.
How resource-intensive applications are defining the data center
Driven by more resource-intensive use cases such as virtual assistants and face recognition, artificial intelligence (AI) and its derivatives are literally re-wiring data center architectures. The complex algorithms needed to drive these applications are developed and modeled deep in the data center core, then pushed out to the edge nodes. Occasionally, data dumps from the edge are sent back to the core and used to refine the algorithm before being pushed back out to the edge. As the cycle of continuous improvement/continuous deployment (CI/CD) successfully repeats, the algorithms and applications become more efficient.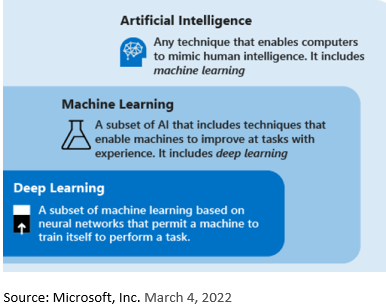
This ebb and flow of data between the edge and core is driven by where the workload needs to be to process and deliver the information most efficiently. Workloads, in turn, are being driven by the deployment of the internet of things at the edge, industrial automation, and still unknown near-future applications.
It is within this complex environment that network managers and designers must plan and implement the physical layer infrastructures needed to connect and support these ecosystems for years to come. With deployments of AI, machine learning (ML) and deep learning on the rise, it is critical to nail the infrastructure from the start.
As the algorithms get faster, more accurate and more precise, these technologies will scale up and out. The right infrastructure will enable that—minimizing the impact on the ecosystem and evolving over time without having to retool the whole network. The challenge is that the environment changes so quickly that we as an industry are, in many respects, having to build the plane as we’re flying it.
But we’re not flying blind; we know some of the immediate hurdles we need to overcome. For instance, we’re already seeing initial deployments of AI and ML push server network speed requirements to 200 gigs and beyond. We know that switch manufacturers are favoring new MPO16 connectors that support eight lanes with 16-fiber interconnections. Currently that is a potential of 800G per network transceiver or, perhaps, eight servers connecting at 100G from a single transceiver. More lanes means more capacity per switch—and that drives lower cost and lower power consumption.
Today, a single high-radix switch supports 256 lanes at 100G per lane, for 25.6T of capacity. Deployed at the edge, these switches provide the same bandwidth as several last-gen models—more than enough to support a large number of servers or devices. Adding a second switch at the edge provides the redundancy and capacity of five or six older models’ switches. More importantly, it enables the data center to create the edge capacity needed to support the CI/CD loop essential for refining the AL and ML algorithms.
A big challenge is that bandwidth is finite and expensive, so network managers must prioritize what information needs to be funneled back to the core and what can remain at the edge. Even defining the location of the edge can be difficult. For a hyperscaler, the edge may be in an MTDC, street-level cabinet, or manufacturing facility located miles from the core. The variety of deployment scenarios and bandwidth requirements dictates the capabilities and configurations of the infrastructure.
Implications for network infrastructure
Adapting to new core-to-edge requirements means network infrastructures must become faster and more flexible. We’re already seeing how speeds of 400G and greater are affecting network designs. Beginning with 400G, more applications are being designed for 16-fiber cabling. This is prompting a shift from traditional quad-based connectivity to octal designs built on 16-fiber MPO breakouts. A 16-fiber configuration doubles the number of breakouts per transceiver and provides long-term support from 400G to 800G, 1.6T and beyond. Look for the 16-fiber design—including matching transceivers, trunk/array cables and distribution modules—to become the basic building block for higher speed core-to-edge connections.
At the same time, data centers need more design flexibility when it comes to redistributing fiber capacity and responding to changes in resource allocation. One way to achieve this is to develop built-in modularity in the panel components. A design in which all panel components are essentially interchangeable and designed to fit in a single, common panel enables designers and installers to quickly reconfigure and deploy fiber capacity as fast as possible and with the lowest cost. So, too, it enables the data center to streamline infrastructure inventory and the associated costs.
Getting the infrastructure right starts now
Next-generation technologies and applications are driven by efficiencies and capabilities that we are still developing. As an industry, when we consider having to re-tool thousands of very large data centers to provide that level of high-efficiency flexibility, getting it right from day one becomes imperative. The foundations of the infrastructure need to be in place before we get too far down the road. Otherwise, the infrastructures that should be enabling growth will prevent it. That doesn’t mean we need to have 100 percent of the requisite capabilities from the start. But we do need to understand what the structure looks like, so we can build out what is needed—where it is needed and before we need it.
At CommScope, we’ve used our 40+ years of infrastructure design experience and input from customers and partners to develop a unique fiber platform that we believe can serve as a model for long-term sustainable growth. To learn more, visit CommScope’s Insights page.
[i] Your data center may not be dead, but it’s morphing; Gartner, report; September 17, 2020













